|
001 |
This chapter describes partitioned tables and indexes. It covers the
following topics:
|
本章讲述分区表(partitioned table)及分区索引(partitioned index)。具体内容如下:
|
|
002 |
Note:
This functionality is available only if you purchase the
Partitioning option.
|
提示:
用户必须购买分区选件(Partitioning option)才能使用相关功能。
|
|
003 |
Introduction to
Partitioning
|
18.1 分区技术简介
|
|
004 |
Partitioning addresses key issues in supporting very large tables
and indexes by letting you decompose them into smaller and more
manageable pieces called partitions. SQL queries and DML
statements do not need to be modified in order to access partitioned
tables. However, after partitions are defined, DDL statements can access
and manipulate individuals partitions rather than entire tables or
indexes. This is how partitioning can simplify the manageability of
large database objects. Also, partitioning is entirely transparent to
applications.
|
分区技术(partitioning)可以将大表、大索引分解为更小、更易管理的块,这些块被称为分区(partition),通过分区技术可以有效地解决大表、大索引带来的问题。用户对分区表执行的
SQL 查询或 DML 语句与对普通数据表的语句一样。但是定义了分区后,DDL
语句可以访问、操作一个单独的分区,而不是整个表或索引,这样通过分区技术就能简化对大数据库对象的管理工作。分区对应用程序是透明的。
|
|
005 |
Each partition of a table or index must have the same logical
attributes, such as column names, datatypes, and constraints, but each
partition can have separate physical attributes such as pctfree, pctused,
and tablespaces.
|
表或索引的所有分区必须具备相同的逻辑结构,例如列名(column
name),数据类型(datatype),及数据约束(constraint)等,但每个分区的物理属性可以不同,例如 pctfree,pctused,及表空间等。
|
|
006 |
Partitioning is useful for many different types of applications,
particularly applications that manage large volumes of data. OLTP
systems often benefit from improvements in manageability and
availability, while data warehousing systems benefit from performance
and manageability.
|
分区技术在多种应用系统中都能发挥作用,其效果在需要管理大量数据的应用系统中尤为显著。OLTP
系统能够利用分区技术提高可管理性(manageability)及可用性(availability),而数据仓库系统则可以通过分区技术提高性能及可管理性。
|
|
007 |
Note:
All partitions of a partitioned object must reside in tablespaces of
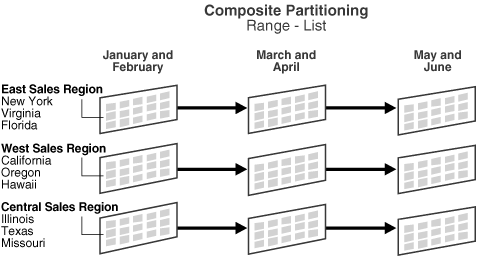
a single block size.
|
提示:
一个分区对象的所有分区必须存储在数据块容量(block size)相同的表空间中。
|
|
008 |
See Also:
|
另见:
|
|
009 |
Partitioning offers these advantages:
- Partitioning enables data management
operations such data loads, index creation and rebuilding, and
backup/recovery at the partition level, rather than on the entire
table. This results in significantly reduced times for these
operations.
- Partitioning improves query
performance. In many cases, the results of a query can be achieved
by accessing a subset of partitions, rather than the entire table.
For some queries, this technique (called
partition pruning)
can provide order-of-magnitude gains in performance.
- Partitioning can significantly reduce
the impact of scheduled downtime for maintenance operations.
- Partition independence for partition
maintenance operations lets you perform concurrent maintenance
operations on different partitions of the same table or index. You
can also run concurrent SELECT and DML
operations against partitions that are unaffected by maintenance
operations.
- Partitioning increases the
availability of mission-critical databases if critical tables and
indexes are divided into partitions to reduce the maintenance
windows, recovery times, and impact of failures.
- Partitioning can be implemented
without requiring any modifications to your applications. For
example, you could convert a nonpartitioned table to a partitioned
table without needing to modify any of the
SELECT statements or DML statements which access that table.
You do not need to rewrite your application code to take advantage
of partitioning.
|
分区技术能够带来以下好处:
- 利用分区技术,用户可以在分区级(partition
level)进行数据加载(data load),索引创建及重建,或备份恢复等数据管理操作,而非针对整个表执行。这大大减少了此类操作所需时间。
-
分区技术能够提高查询性能。在很多情况下,查询的结果集可能来自几个分区,而非整个表。 对于某些查询,这种技术(称为分区剪除(partition pruning))能够带来几个数据量级的性能提升。
- 分区技术能够显著缩短维护操作导致的停机时间。
-
由于对各分区的维护操作可以相互独立地进行,用户可以同时对表或索引的不同分区进行维护操作。用户还能在维护的同时对未受维护操作影响的分区执行
SELECT 及 DML 操作。
-
利用分区技术存储数据库中的关键表及索引,能够缩短此类对象的维护窗口(maintenance
window),及恢复时间,并减少此类对象发生故障时对系统的影响,从而提高数据库的可用性。
-
采用分区技术时,用户无需对原有应用程序进行任何修改。例如,当用户将一个非分区表转化为分区表后,无需修改访问此表的
SELECT 语句及 DML 语句。用户无需重写应用程序代码就可以发挥分区技术的优势。
|
|
010 |
Figure 18-1 offers a graphical
view of how partitioned tables differ from nonpartitioned tables.
|
图 18-1 展示了分区表与非分区表之间的区别。
|
|
011 |
Figure
18-1 A View of Partitioned Tables
|
图 18-1 分区表图示
|
|
012 |

|
 |
|
013 |
Figure 18-1 shows that both partitioned and
non-partitioned tables can each have partitioned or non-partitioned
indexes.
|
图 18-1 显示了分区表及非分区表既可以使用分区索引,也可以使用非分区索引。
|
|
014 |
Partition Key
|
18.1.1 分区键
|
|
015 |
Each row in a partitioned table is unambiguously assigned to a single
partition. The partition key is a set of one or more columns that
determines the partition for each row. Oracle automatically directs
insert, update, and delete operations to the appropriate partition
through the use of the partition key. A partition key:
- Consists of an ordered list of 1 to 16
columns
- Cannot contain a
LEVEL, ROWID, or
MLSLABEL pseudocolumn or a column of
type ROWID
- Can contain columns that are
NULLable
|
分区表(partitioned
table)内的每个数据行都能且只能分配到一个分区中(partition)。分区键(partition key)是决定数据行属于哪个分区的一组数据列。Oracle
在执行插入,更新,及删除操作时能根据分区键自动地选择分区。分区键的特点如下:
- 由 1 至 16 个数据列顺序构成
- 不能包含
LEVEL,ROWID,或
MLSLABEL 虚列(pseudocolumn),也不能包含类型为 ROWID
的列
- 不能包含可为空(NULLable)的列
|
|
016 |
Partitioned Tables
|
18.1.2 分区表
|
|
017 |
Tables can be partitioned into up to 1024K-1 separate partitions. Any
table can be partitioned except those tables containing columns with
LONG or LONG RAW
datatypes. You can, however, use tables containing columns with
CLOB or BLOB
datatypes.
|
一个表最多可由 1024K-1 个分区构成。任何表都能够被分区,除非其中含有数据类型为
LONG 或 LONG RAW
的列。注意,含
CLOB 或 BLOB
类型列的表可以被分区。
|
|
018 |
Note:
To reduce disk use and memory use (specifically, the buffer cache),
you can store tables and partitioned tables in a compressed format
inside the database. This often leads to a better scaleup for
read-only operations. Table compression can also speed up query
execution. There is, however, a slight cost in CPU overhead.
|
提示:
为了减少磁盘及内存空间(尤其是数据库缓存(buffer
cache))的使用,用户可以采用压缩的形式存储表及分区表。这有助于提高只读操作的可伸缩性(scaleup)。表压缩还能提升查询的执行速度
,但会造成一些额外的
CPU 开销。
|
|
019 |
See Also:
"Table Compression"
|
另见:
“表压缩”
|
|
020 |
Partitioned Index-Organized Tables
|
18.1.3 分区索引表
|
|
021 |
You can partition index-organized tables by range, list, or hash.
Partitioned index-organized tables are very useful for providing
improved manageability, availability, and performance for
index-organized tables. In addition, data cartridges that use
index-organized tables can take advantage of the ability to partition
their stored data. Common examples of this are the Image and interMedia
cartridges.
|
用户可以依据范围(range),列表(list),或哈希算法(hash)将索引表(index-organized
table)分区。将索引表分区能够有效地提高其可管理性,可用性,及性能。此外,data cartridge
能够借助索引表对其数据进行分区。例如,Image cartridge 及 interMedia cartridge 可以采取此种方式进行分区。
|
|
022 |
For partitioning an index-organized table:
- Partition columns must be a subset of
primary key columns
-
Secondary indexes can be partitioned —
locally and globally
- OVERFLOW
data segments are always equipartitioned with the table partitions
|
在对索引表进行分区时:
- 分区列(partition column)必须是主键列(primary
key column)的子集
- 辅助索引(secondary
index)可以采用本地(locally)分区或全局(globally)分区
- OVERFLOW
数据段的分区方式与表分区相同
|
|
023 |
Overview of
Partitioning Methods
|
18.2 分区方法概述
|
|
024 |
Oracle provides the following partitioning methods:
|
Oracle 提供了一下几种分区方法:
|
|
025 |
Figure 18-2 offers a graphical
view of the methods of partitioning.
|
图 18-2 展示了几种分区方法。
|
|
026 |
Figure 18-2 List, Range, and
Hash Partitioning
|
图 18-2 列表分区,范围分区,及哈系分区
|
|
027 |

|

|
|
028 |
Figure 18-2 shows list partitioning by sales region,
range partitioning by two month periods, and hash partitioning by
hash group (h1, h2, h3, and h4).
|
图 18-2
显示了依据销售区域进行列表分区,以两个月为一区间进行范围分区,以及按哈希组(h1,h2,h3,h4)进行哈希分区。
|
|
029 |
Composite partitioning is a combination of other partitioning methods.
Oracle supports range-hash and range-list composite partitioning.
Figure 18-3 offers a graphical
view of range-hash and range-list composite partitioning.
|
用户还可以将多种分区方法组合进行复合分区(composite partitioning)。Oracle
支持范围-哈希(range-hash)复合分区及范围-列表(range-list)复合分区。图 18-3
展示了这两种复合分区。
|
|
030 |
Figure 18-3 Composite
Partitioning
|
图 18-3 复合分区
|
|
031 |

|
 |
|
032 |
Figure 18-3 shows composite partitioning with
range-hash partitioning (h1, h2, h3, and h4) and composite
partitioning with range-list partitioning (with geographical regions
in various time periods (January and February, March and April, May
and June).
|
图 18-3
显示了使用哈希组(h1,h2,h3,h4)的范围-哈希复合分区,以及范围-列表复合分区(时间区间(January 到 February,March
到 April,May 到 June)及地理区域列表)。
|
|
033 |
Range Partitioning
|
18.2.1 范围分区
|
|
034 |
Range partitioning maps data to partitions based on ranges of partition
key values that you establish for each partition. It is the most common
type of partitioning and is often used with dates. For example, you
might want to partition sales data into monthly partitions.
|
范围分区(range partitioning)依据用户创建分区时设定的分区键值(partition key
value)范围将数据映射到不同分区。范围分区是较常用的分区方式,通常针对日期数据使用。例如,用户可以将销售数据按月存储到相应的分区中。
|
|
035 |
When using range partitioning, consider the following rules:
- Each partition has a
VALUES LESS THAN clause, which
specifies a noninclusive upper bound for the partitions. Any values
of the partition key equal to or higher than this literal are added
to the next higher partition.
- All partitions, except the first, have
an implicit lower bound specified by the
VALUES LESS THAN clause on the previous partition.
- A MAXVALUE
literal can be defined for the highest partition.
MAXVALUE represents a virtual infinite
value that sorts higher than any other possible value for the
partition key, including the null value.
|
在采用范围分区时,应注意以下规则:
- 定义分区时必须使用
VALUES LESS THAN
子句定义分区的开区间上限(noninclusive upper
bound)。分区键大于等于此修饰符(literal)的数据将被存储到下一个分区中。
- 除了第一个分区之外,其他所有分区都有一个隐式的下限(lower
bound),此下限是由上一个分区的
VALUES LESS THAN 子句指定的。
- 用户可以为最大分区定义一个 MAXVALUE
修饰符。MAXVALUE
代表一个无穷大值,用于识别大于所有可能分区键的数据(包括 null)。
|
|
036 |
A typical example is given in the following section. The statement
creates a table (sales_range) that is range
partitioned on the sales_date field.
|
下面的语句给出一个典型的范围例子。此语句创建了依据 sales_date
字段进行范围分区的表 sales_range。
|
|
037 |
Range Partitioning Example
|
18.2.1.1 范围分区示例
|
|
038 |
CREATE TABLE sales_range (
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)(
PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('02/01/2000','MM/DD/YYYY')),
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('03/01/2000','MM/DD/YYYY')),
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('04/01/2000','MM/DD/YYYY')),
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('05/01/2000','MM/DD/YYYY'))
);
|
CREATE TABLE sales_range (
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)(
PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('02/01/2000','MM/DD/YYYY')),
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('03/01/2000','MM/DD/YYYY')),
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('04/01/2000','MM/DD/YYYY')),
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('05/01/2000','MM/DD/YYYY'))
);
|
|
039 |
List Partitioning
|
18.2.2 列表分区
|
|
040 |
List partitioning enables you to explicitly control how rows map to
partitions. You do this by specifying a list of discrete values for the
partitioning key in the description for each partition. This is
different from range partitioning, where a range of values is associated
with a partition and from hash partitioning, where a hash function
controls the row-to-partition mapping. The advantage of list
partitioning is that you can group and organize unordered and unrelated
sets of data in a natural way.
|
用户可以采用列表分区(list
partitioning)显示地控制如何将数据行映射到各个分区。用户在各分区的定义中指定一个分区键(partitioning
key)离散值的列表,从而实现列表分区。列表分区与范围分区(range
partitioning)有所不同,在范围分区中是为每个分区设定一个分区键值的范围;列表分区与哈希分区也有区别,哈希分区是通过一个哈希函数(hash
function)控制数据行与分区间的映射关系。用户可以采用列表分区,将无序(unordered)或互不相关(unrelated)的数据进行分组整理。
|
|
041 |
The details of list partitioning can best be described with an example.
In this case, let's say you want to partition a sales table by region.
That means grouping states together according to their geographical
location as in the following example.
|
下面是一个列表分区的示例。在此例子中,用户需要按区域对销售数据进行分区。即把地理位置接近的州归为一组。
|
|
042 |
List Partitioning Example
|
18.2.2.1 范围分区示例
|
|
043 |
CREATE TABLE sales_list(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY LIST(sales_state)(
PARTITION sales_west VALUES('California', 'Hawaii'),
PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'),
PARTITION sales_central VALUES('Texas', 'Illinois'),
PARTITION sales_other VALUES(DEFAULT)
);
|
CREATE TABLE sales_list(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY LIST(sales_state)(
PARTITION sales_west VALUES('California', 'Hawaii'),
PARTITION sales_east VALUES ('New York', 'Virginia', 'Florida'),
PARTITION sales_central VALUES('Texas', 'Illinois'),
PARTITION sales_other VALUES(DEFAULT)
);
|
|
044 |
A row is mapped to a partition by checking whether the value of the
partitioning column for a row falls within the set of values that
describes the partition. For example, the rows are inserted as follows:
- (10,
'Jones', 'Hawaii',
100,
'05-JAN-2000') maps to partition
sales_west
- (21,
'Smith',
'Florida', 150,
'15-JAN-2000') maps to partition
sales_east
- (32,
'Lee', 'Colorado',
130,
'21-JAN-2000') maps to partition
sales_other
|
在将数据行映射到分区的过程中,Oracle 检查数据行的分区键值是否包含于某分区定义的值列中。以下面的数据为例:
- (10,'Jones','Hawaii',100,'05-JAN-2000')
映射到
sales_west 分区
- (21,'Smith','Florida',150,'15-JAN-2000')
映射到
sales_east 分区
- (32,'Lee','Colorado',130,'21-JAN-2000')
映射到
sales_other 分区
|
|
045 |
Unlike range and hash partitioning, multicolumn partition keys are not
supported for list partitioning. If a table is partitioned by list, the
partitioning key can only consist of a single column of the table.
|
与范围分区(range partitioning)及哈希分区(hash
partitioning)有所区别,列表分区不支持分区键中包含多列。如果一个表采用列表分区方式,那么分区键只能由此表的一个数据列构成。
|
|
046 |
The DEFAULT partition enables you to avoid
specifying all possible values for a list-partitioned table by using a
default partition, so that all rows that do not map to any other
partition do not generate an error.
|
用户可以定义一个 DEFAULT
分区,在定义了此分区后,定义列表分区表时不必列出所有可能的分区键值,Oracle 在处理数据时也不会出现无法映射的情况。
|
|
047 |
Hash Partitioning
|
18.2.3 哈希分区
|
|
048 |
Hash partitioning enables easy partitioning of data that does not lend
itself to range or list partitioning. It does this with a simple syntax
and is easy to implement. It is a better choice than range partitioning
when:
- You do not know beforehand how much
data maps into a given range
- The sizes of range partitions would
differ quite substantially or would be difficult to balance manually
-
Range partitioning would cause the
data to be undesirably clustered
- Performance features such as parallel
DML, partition pruning, and partition-wise joins are important
|
用户可以采用哈希分区(hash partitioning)将不适于采用范围分区(range partitioning)或列表分区(list
partitioning)的数据进行分区。哈希分区的语法(syntax)简单且易于实现。在以下情况时哈希分区比范围分区更适用:
- 用户无法事先确定一个分区可能存储的数据量
- 各范围分区的容量可能相差很大,或很难通过人工进行平衡
- 采用范围分区可能导致数据不正常的集中
- 应用系统对并行 DML(parallel DML),分区剪除(partition
pruning),及基于分区的关联(partition-wise joins)等与性能有关的分区特性要求较高
|
|
049 |
The concepts of splitting, dropping or merging partitions do not apply
to hash partitions. Instead, hash partitions can be added and
coalesced.
|
分割(splitting),移除(dropping
),及融合(merging)等操作不适用于哈希分区。但对哈希分区可以进行添加(add)及接合(coalesce)操作。
|
|
050 |
See Also:
Oracle Database Administrator's Guide for more information about
partition tasks such as splitting partitions
|
另见:
Oracle Database Administrator's Guide
了解关于分割等分区操作的详细信息
|
|
051 |
Hash Partitioning Example
|
18.2.3.1 哈希分区示例
|
|
052 |
CREATE TABLE sales_hash(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
PARTITIONS 4
STORE IN (ts1, ts2, ts3, ts4);
|
CREATE TABLE sales_hash(
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
week_no NUMBER(2))
PARTITION BY HASH(salesman_id)
PARTITIONS 4
STORE IN (ts1, ts2, ts3, ts4);
|
|
053 |
The preceding statement creates a table sales_hash,
which is hash partitioned on salesman_id
field. The tablespace names are ts1,
ts2, ts3, and
ts4.
With this syntax, we ensure that we
create the partitions in a round-robin manner across the specified
tablespaces.
|
上述语句创建了依据 salesman_id
字段进行哈希分区(hash partitioning)的分区表 sales_hash。此表使用的表空间分别为 ts1,ts2,ts3,及
ts4。上述语句表明,将数据以循环(round-robin)的方式存储到语句中指定的各个表空间中。
|
|
054 |
Composite Partitioning
|
18.2.4 复合分区
|
|
055 |
Composite partitioning partitions data using the range method, and
within each partition, subpartitions it using the hash or list method.
Composite range-hash partitioning provides the improved manageability of
range partitioning and the data placement, striping, and parallelism
advantages of hash partitioning. Composite range-list partitioning
provides the manageability of range partitioning and the explicit
control of list partitioning for the subpartitions.
|
复合分区(composite
partitioning)首先根据范围(range)进行分区,再使用哈希或列表方式创建子分区。复合范围-哈希分区既能够发挥范围分区的可管理性优势,也能够发挥哈希分区的数据分布(data
placement),条带化(striping),及并行化(parallelism)优势。复合范围-列表分区能够发挥范围分区的可管理性优势,也能利用列表分区的显示控制能力。
|
|
056 |
Composite partitioning supports historical operations, such as adding
new range partitions, but also provides higher degrees of parallelism
for DML operations and finer granularity of data placement through
subpartitioning.
|
复合分区(composite partitioning)便于用户进行与时间相关的维护操作(historical
operation),例如添加新的范围分区等。同时复合分区还能够利用子分区(subpartitioning)实现高度的并行 DML
操作,并对数据分布进行精细的控制。
|
|
057 |
Composite Partitioning Range-Hash Example
|
18.2.4.1 复合范围-哈希分区示例
|
|
058 |
CREATE TABLE sales_composite (
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
SUBPARTITION BY HASH(salesman_id)
SUBPARTITION TEMPLATE(
SUBPARTITION sp1 TABLESPACE ts1,
SUBPARTITION sp2 TABLESPACE ts2,
SUBPARTITION sp3 TABLESPACE ts3,
SUBPARTITION sp4 TABLESPACE ts4)
(PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('02/01/2000','MM/DD/YYYY'))
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('03/01/2000','MM/DD/YYYY'))
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('04/01/2000','MM/DD/YYYY'))
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('05/01/2000','MM/DD/YYYY'))
PARTITION sales_may2000 VALUES LESS
THAN(TO_DATE('06/01/2000','MM/DD/YYYY')));
|
CREATE TABLE sales_composite (
salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY RANGE(sales_date)
SUBPARTITION BY HASH(salesman_id)
SUBPARTITION TEMPLATE(
SUBPARTITION sp1 TABLESPACE ts1,
SUBPARTITION sp2 TABLESPACE ts2,
SUBPARTITION sp3 TABLESPACE ts3,
SUBPARTITION sp4 TABLESPACE ts4)
(PARTITION sales_jan2000 VALUES LESS
THAN(TO_DATE('02/01/2000','MM/DD/YYYY'))
PARTITION sales_feb2000 VALUES LESS
THAN(TO_DATE('03/01/2000','MM/DD/YYYY'))
PARTITION sales_mar2000 VALUES LESS
THAN(TO_DATE('04/01/2000','MM/DD/YYYY'))
PARTITION sales_apr2000 VALUES LESS
THAN(TO_DATE('05/01/2000','MM/DD/YYYY'))
PARTITION sales_may2000 VALUES LESS
THAN(TO_DATE('06/01/2000','MM/DD/YYYY')));
|
|
059 |
This statement creates a table sales_composite
that is range partitioned on the sales_date
field and hash subpartitioned on salesman_id.
When you use a template, Oracle names the subpartitions by concatenating
the partition name, an underscore, and the subpartition name from the
template. Oracle places this subpartition in the tablespace specified in
the template. In the previous statement,
sales_jan2000_sp1 is created and placed in tablespace
ts1 while
sales_jan2000_sp4 is created and placed in tablespace
ts4. In the same manner,
sales_apr2000_sp1 is created and placed in
tablespace ts1 while
sales_apr2000_sp4 is created and placed in tablespace
ts4. Figure 18-4 offers a graphical view of
the previous example.
|
上述语句创建了 sales_composite
表,首先依据 sales_date
字段创建范围分区(range partitioned),再依据 salesman_id
字段创建哈希子分区。如果用户在语句中使用了模板(template),Oracle
命名子分区的模式为“分区名”加“下划线”再加模板中设定的“子分区名”。同样,Oracle 将子分区存储在模板中指定的表空间中。在上述语句中,子分区
sales_jan2000_sp1 存储在表空间
ts1 中,而子分区
sales_jan2000_sp4 存储在表空间
ts4 中。同样,子分区
sales_apr2000_sp1 存储在表空间 ts1
中,而子分区
sales_apr2000_sp4 存储在表空间
ts4 中。图 18-4
为上述语句的图形化描述。
|
|
060 |
Figure 18-4 Composite
Range-Hash Partitioning
|
图 18-4 复合范围-哈希分区
|
|
061 |

|
 |
|
062 |
Composite Partitioning Range-List Example
|
18.2.4.2 复合范围-列表分区示例
|
|
063 |
CREATE TABLE bimonthly_regional_sales(
deptno NUMBER,
item_no VARCHAR2(20),
txn_date DATE,
txn_amount NUMBER,
state VARCHAR2(2))
PARTITION BY RANGE (txn_date)
SUBPARTITION BY LIST (state)
SUBPARTITION TEMPLATE(
SUBPARTITION east VALUES('NY', 'VA', 'FL') TABLESPACE ts1,
SUBPARTITION west VALUES('CA', 'OR', 'HI') TABLESPACE ts2,
SUBPARTITION central VALUES('IL', 'TX', 'MO') TABLESPACE ts3)
(
PARTITION janfeb_2000 VALUES LESS THAN
(TO_DATE('1-MAR-2000','DD-MON-YYYY')),
PARTITION marapr_2000 VALUES LESS THAN
(TO_DATE('1-MAY-2000','DD-MON-YYYY')),
PARTITION mayjun_2000 VALUES LESS THAN
(TO_DATE('1-JUL-2000','DD-MON-YYYY'))
);
|
CREATE TABLE bimonthly_regional_sales(
deptno NUMBER,
item_no VARCHAR2(20),
txn_date DATE,
txn_amount NUMBER,
state VARCHAR2(2))
PARTITION BY RANGE (txn_date)
SUBPARTITION BY LIST (state)
SUBPARTITION TEMPLATE(
SUBPARTITION east VALUES('NY', 'VA', 'FL') TABLESPACE ts1,
SUBPARTITION west VALUES('CA', 'OR', 'HI') TABLESPACE ts2,
SUBPARTITION central VALUES('IL', 'TX', 'MO') TABLESPACE ts3)
(
PARTITION janfeb_2000 VALUES LESS THAN
(TO_DATE('1-MAR-2000','DD-MON-YYYY')),
PARTITION marapr_2000 VALUES LESS THAN
(TO_DATE('1-MAY-2000','DD-MON-YYYY')),
PARTITION mayjun_2000 VALUES LESS THAN
(TO_DATE('1-JUL-2000','DD-MON-YYYY'))
);
|
|
064 |
This statement creates a table
bimonthly_regional_sales that is range partitioned on the
txn_date field and list subpartitioned on
state. When you use a template, Oracle
names the subpartitions by concatenating the partition name, an
underscore, and the subpartition name from the template. Oracle places
this subpartition in the tablespace specified in the template. In the
previous statement, janfeb_2000_east is
created and placed in tablespace ts1 while
janfeb_2000_central is created and placed
in tablespace ts3. In the same manner,
mayjun_2000_east is placed in tablespace
ts1 while
mayjun_2000_central is placed in tablespace
ts3. Figure 18-5 offers a graphical view of the table
bimonthly_regional_sales and its 9
individual subpartitions.
|
上述语句创建了
bimonthly_regional_sales 表,首先依据
txn_date 字段创建范围分区(range partitioned),再依据
state
字段创建子分区。如果用户在语句中使用了模板(template),Oracle
命名子分区的模式为“分区名”加“下划线”再加模板中设定的“子分区名”。同样,Oracle 将子分区存储在模板中指定的表空间中。在上述语句中,子分区 janfeb_2000_east
存储在表空间 ts1 中,而子分区
janfeb_2000_central 存储在表空间 ts3
中。同样,子分区 mayjun_2000_east 存储在表空间
ts1 中,而子分区
mayjun_2000_central 存储在表空间
ts3 中。图 18-5 显示了表
bimonthly_regional_sales 的 9 个子分区。
|
|
065 |
Figure 18-5 Composite
Range-List Partitioning
|
图 18-5 复合范围-列表分区
|
|
066 |
|

|
|
067 |
When to Partition a Table
|
18.2.5 何时应该对表进行分区
|
|
068 |
Here are some suggestions for when to partition a table:
- Tables greater than 2GB should always
be considered for partitioning.
- Tables containing historical data, in
which new data is added into the newest partition. A typical example
is a historical table where only the current month's data is
updatable and the other 11 months are read only.
|
以下是关于何时应该对表进行分区的一些建议:
- 如果表数据量超过 2GB,就应该考虑进行分区。
-
如果表中包含历史数据,且新数据会被添加到最新的表空间中。典型的例子是一种历史表,其中只有当前月份的数据可以被修改,而其他十一个月的数据为只读。
|
|
069 |
Overview of
Partitioned Indexes
|
18.3 分区索引概述
|
|
070 |
Just like partitioned tables, partitioned indexes improve manageability,
availability, performance, and scalability. They can either be
partitioned independently (global indexes) or automatically linked to a
table's partitioning method (local indexes). In general, you should use
global indexes for OLTP applications and local indexes for data
warehousing or DSS applications. Also, whenever possible, you should try
to use local indexes because they are easier to manage. When deciding
what kind of partitioned index to use, you should consider the following
guidelines in order:
- If the table partitioning column is a
subset of the index keys, use a local index. If this is the case,
you are finished. If this is not the case, continue to guideline 2.
- If the index is unique, use a global
index. If this is the case, you are finished. If this is not the
case, continue to guideline 3.
- If your priority is manageability, use
a local index. If this is the case, you are finished. If this is not
the case, continue to guideline 4.
- If the application is an OLTP one and
users need quick response times, use a global index. If the
application is a DSS one and users are more interested in
throughput, use a local index.
|
与分区表类似(partitioned table),分区索引(partitioned
index)也能够提高系统的可管理性,可用性,可伸缩性,及系统性能。分区索引既可以与分区表相对独立(全局索引(global
index)),也可以采用与分区表相同的分区方式(本地索引(local index))。一般来说,OLTP
系统适合采用全局索引,而数据仓库系统或 DSS
系统适合采用本地索引。此外,用户应尽可能地使用本地索引,因为此种索引更易管理。在选择索引类型时,可以参考以下经验:
- 如果表的分区键(partitioning column)是索引键(index
key)的子集,应使用本地索引。否则继续参考经验 2。
- 如果索引为唯一索引(unique),应使用全局索引。否则继续参考经验 3。
- 如果用户对可管理性的要求更高,应使用本地索引。否则继续参考经验 4。
- 如果应用系统为
OLTP,且对系统的响应时间要求较高,应使用全局索引。如果应用系统为 DSS,且对系统的数据吞吐量要求较高,应使用本地索引。
|
|
071 |
See Also:
Oracle Database Data Warehousing Guide and
Oracle Database Administrator's Guide for more information about
partitioned indexes and how to decide which type to use
|
另见:
Oracle Database Data Warehousing Guide
与
Oracle Database Administrator's Guide
了解分区索引,及如何选择索引类型
|
|
072 |
Local Partitioned Indexes
|
18.3.1 本地分区索引
|
|
073 |
Local partitioned indexes are easier to manage than other types of
partitioned indexes. They also offer greater availability and are common
in DSS environments. The reason for this is equipartitioning: each
partition of a local index is associated with exactly one partition of
the table. This enables Oracle to automatically keep the index
partitions in sync with the table partitions, and makes each table-index
pair independent. Any actions that make one partition's data invalid or
unavailable only affect a single partition.
|
本地分区索引(local partitioned index)与其他类型分区索引相比较更易管理。本地分区索引适用于 DSS
系统,且具有较高的可用性。这是因为本地分区索引与其所在的分区表采用相同的分区方式:本地分区索引的每个分区都与分区表的一个分区相对应。因此,Oracle
能够自动地确保各个索引分区与相应的表分区同步,且使各个表-索引分区对(table-index
pair)相互独立。当一个表分区内的数据发生变化时,只会影响一个索引分区。
|
|
074 |
Local partitioned indexes support more availability when there are
partition or subpartition maintenance operations on the table.
A type of
index called a local nonprefixed index is very useful for historical
databases. In this type of index, the partitioning is not on the left
prefix of the index columns.
|
当对表的分区及子分区进行维护操作时,本地分区索引与全局索引相比具备更高的可用性。有一种索引被称为本地非前缀分区索引(local nonprefixed
index)非常适合用于存取历史数据。此类索引的特点是,不对索引键的左前缀进行分区。
|
|
075 |
See Also:
Oracle Database Data Warehousing Guide more information
about prefixed indexes
|
另见:
Oracle Database Data Warehousing Guide
了解更多关于前缀索引的信息
|
|
076 |
You cannot explicitly add a partition to a local index. Instead, new
partitions are added to local indexes only when you add a partition to
the underlying table. Likewise, you cannot explicitly drop a partition
from a local index. Instead, local index partitions are dropped only
when you drop a partition from the underlying table.
|
用户不能显示地向本地分区索引中添加分区。当用户为分区表添加分区时,相应的索引分区会被自动添加。同样,用户也不能显示地移除本地分区索引中的分区。当用户从分区表中移除分区时,相应的索引分区会被自动移除。
|
|
077 |
A local index can be unique. However, in order for a local index to be
unique, the partitioning key of the table must be part of the index's
key columns. Unique local indexes are useful for OLTP environments.
|
本地分区索引可以是唯一索引。但是,为了确保本地分区索引每个分区的唯一性,分区键必须是索引键的子集。通常唯一本地分区索引适用于 OLTP 系统。
|
|
078 |
Figure 18-6 offers a graphical view of local partitioned indexes.
|
图 18-6 展示了本地分区索引。
|
|
079 |
Figure 18-6 Local
Partitioned Index
|
图 18-6 本地分区索引
|
|
080 |

|

|
|
081 |
Global Partitioned Indexes
|
18.3.2 全局分区索引
|
|
082 |
Oracle offers two types of global partitioned index: range partitioned
and hash partitioned.
|
Oracle 支持两种全局分区索引(global partitioned index):范围(range)分区索引及哈希(hash)分区索引。
|
|
083 |
Global Range Partitioned Indexes
|
18.3.2.1 全局范围分区索引
|
|
084 |
Global range partitioned indexes are flexible in that the degree of
partitioning and the partitioning key are independent from the table's
partitioning method. They are commonly used for OLTP environments and
offer efficient access to any individual record.
|
全局范围分区索引(global range partitioned index)的灵活性在于其分区度(degree of
partitioning)及分区键(partitioning key )都可以和表的分区方法相独立。此类索引主要用于 OLTP
系统,在存取独立记录时效率较高。
|
|
085 |
The highest partition of a global index must have a partition bound, all
of whose values are
MAXVALUE. This ensures
that all rows in the underlying table can be represented in the index.
Global prefixed indexes can be unique or nonunique.
|
全局范围分区索引的最后一个分区必须使用 MAXVALUE
设置一个分区边界。这能保证所有表数据都能反映到索引中。全局前缀索引(global prefixed index)可以是唯一的或非唯一的。
|
|
086 |
You cannot add a partition to a global index because the highest
partition always has a partition bound of
MAXVALUE.
If you wish to add a new highest partition, use the
ALTER INDEX SPLIT PARTITION statement. If a
global index partition is empty, you can explicitly drop it by issuing
the
ALTER INDEX DROP PARTITION statement.
If a global index partition contains data, dropping the partition causes
the next highest partition to be marked unusable. You cannot drop the
highest partition in a global index.
|
用户不能向全局范围分区索引中添加分区,因为最后一个分区总是以 MAXVALUE
作为分区边界。如果用户需要添加最高分区,应使用
ALTER INDEX SPLIT PARTITION
语句。如果一个全局索引的某分区已空,用户可以使用 ALTER INDEX DROP PARTITION
显示地将其移除。如果全局索引的某个分区内含有数据,移除此分区将导致下一个分区被标识为不可用。用户不能移除全局索引中的最后一个分区。
|
|
087 |
Global Hash Partitioned Indexes
|
18.3.2.2 全局哈希分区索引
|
|
088 |
Global hash partitioned indexes improve performance by spreading out
contention when the index is monotonically growing. In other words, most
of the index insertions occur only on the right edge of an index.
|
对于索引值单调增长的表,创建全局哈希分区索引(lobal hash partitioned
index)有助于索引数据分布,从而提升系统性能。索引值单调增长指新索引数据只会在索引的右边界插入。
|
|
089 |
Maintenance of Global Partitioned Indexes
|
18.3.2.3 全局分区索引的维护
|
|
090 |
By default, the following operations on partitions on a heap-organized table mark all global indexes as unusable:
ADD (HASH)
COALESCE (HASH)
DROP
EXCHANGE
MERGE
MOVE
SPLIT
TRUNCATE
|
在一般情况下,对全局索引所在的堆表(heap-organized table)进行以下操作将导致索引被标识为不可用:
ADD (HASH)
COALESCE (HASH)
DROP
EXCHANGE
MERGE
MOVE
SPLIT
TRUNCATE
|
|
091 |
These indexes can be maintained by appending the clause
UPDATE INDEXES to the SQL statements for
the operation. The two advantages to maintaining global indexes:
- The index remains available and online
throughout the operation. Hence no other applications are affected
by this operation.
- The index doesn't have to be rebuilt
after the operation.
|
用户可以在上述操作的 SQL 语句后添加
UPDATE INDEXES
子句,以便维护全局分区索引。这样对索引进行维护的好处有两个:
- 在操作期间索引依然有效。因此其他应用程序不会受相关操作的影响。
- 在操作结束后索引不必重建。
|
|
092 |
Example:
ALTER TABLE DROP PARTITION P1 UPDATE INDEXES;
|
示例:
ALTER TABLE DROP PARTITION P1 UPDATE INDEXES;
|
|
093 |
Note:
This feature is supported only for heap-organized tables.
|
提示:
只有堆表支持此功能。
|
|
094 |
See Also:
Oracle Database SQL Reference for more information about the
UPDATE INDEXES clause
|
另见:
Oracle Database SQL Reference
了解关于 UPDATE INDEXES 子句的更多信息
|
|
095 |
Figure 18-7 offers a graphical view of global partitioned indexes.
|
图 18-7 展示了全局分区索引。
|
|
096 |
Figure 18-7 Global
Partitioned Index
|
图 18-7 全局分区索引
|
|
097 |

|

|
|
098 |
Figure 18-7 shows that global partitioned indexes can
point to different tables.
|
图 18-7 全局分区索引的一个分区可以指向不同的表分区。
|
|
099 |
Global Nonpartitioned Indexes
|
18.3.3 全局非分区索引
|
|
100 |
Global nonpartitioned indexes behave just like a nonpartitioned index.
They are commonly used in OLTP environments and offer efficient access
to any individual record.
|
全局非分区索引(global nonpartitioned index)与普通的非分区索引类似。此类索引主要用于 OLTP
系统,在存取独立记录时效率较高。
|
|
101 |
Figure 18-8 offers a graphical view of global nonpartitioned indexes.
|
图 18-8 展示了全局非分区索引。
|
|
102 |
Figure 18-8 Global
Nonpartitioned Index
|
图 18-8 全局非分区索引
|
|
103 |

|

|
|
104 |
Figure 18-8 shows that a global nonpartitioned index
can point to different tables.
|
图 18-8 显示了全局非分区索引可以指向分区表的不同分区。
|
|
105 |
Miscellaneous Information about Creating
Indexes on Partitioned Tables
|
18.3.4 在分区表上创建索引的其他知识
|
|
106 |
You can create bitmap indexes on partitioned tables, with the
restriction that the bitmap indexes must be local to the partitioned
table. They cannot be global indexes.
|
用户可以在分区表上创建位图索引(bitmap index),但必须是本地分区索引(local partitioned
index),而不能是全局索引(global index)。
|
|
107 |
Global indexes can be unique. Local indexes can only be unique if the
partitioning key is a part of the index key.
|
全局索引(global index)可以是唯一的。如果分区键是索引键的子集,本地索引只能是唯一的。
|
|
108 |
Using Partitioned Indexes in OLTP
Applications
|
18.3.5 在 OLTP 系统中使用分区索引
|
|
109 |
Here are a few guidelines for OLTP applications:
- Global indexes and unique, local
indexes provide better performance than nonunique local indexes
because they minimize the number of index partition probes.
- Local indexes offer better
availability when there are partition or subpartition maintenance
operations on the table.
- Hash-partitioned global indexes offer
better performance by spreading out contention when the index is
monotonically growing. In other words, most of the index insertions
occur only on the right edge of an index.
|
以下是在 OLTP 系统中使用分区索引的一些指导建议:
- 全局分区索引(global partitioned
index)及唯一本地分区索引(unique local partitioned index)与非唯一本地分区索引(nonunique
local partitioned index)相比能够提供更好的性能。前两者能够最小化需要被检索的索引分区。
- 在对表的分区或子分区进行维护时,本地分区索引具备更高的可用性。
- 全局哈希分区索引(global hash-partitioned index)在索引值单调增长的情况下能够
均匀分布索引数据,从而提升系统性能。索引值单调增长指新索引数据只会插入到索引的右边界外。
|
|
110 |
Using Partitioned Indexes in Data Warehousing
and DSS Applications
|
18.3.6 在数据仓库及 DDS 系统中使用分区索引
|
|
111 |
Here are a few guidelines for data warehousing and DSS applications:
- Local indexes are preferable because
they are easier to manage during data loads and during
partition-maintenance operations.
- Local indexes can improve performance
because many index partitions can be scanned in parallel by range
queries on the index key.
|
以下是在数据仓库系统及 DSS 系统中使用分区索引的一些指导建议:
- 应尽可能地使用本地分区索引(local partitioned
index),因为此类索引在数据加载过程中及进行分区维护操作时更易管理(data load)
-
本地分区索引有助于提升系统性能,因为对一个范围内的索引键进行查询时,可以并行地扫描多个分区。
|
|
112 |
Partitioned Indexes on Composite Partitions
|
18.3.7 复合分区上的分区索引
|
|
113 |
Here are a few points to remember when using partitioned indexes on
composite partitions:
- Subpartitioned indexes are always
local and stored with the table subpartition by default.
-
Tablespaces can be specified at either
index or index subpartition levels.
|
以下是关于在复合分区(composite partition)上创建分区索引(partitioned index)的一些建议:
- 子分区索引(subpartitioned
index)必须是本地的,且默认与表的子分区存储在一起。
- 用户既可以为整个索引设定表空间,也可以分别为索引子分区设定表空间。
|
|
114 |
Partitioning to
Improve Performance
|
18.4 利用分区技术提高系统性能
|
|
115 |
Partitioning can help you improve performance and manageability. Some
topics to keep in mind when using partitioning for these reasons are:
|
分区技术能够帮助用户提高系统的性能及可管理性。为实现上述目标,用户应了解以下问题:
|
|
116 |
Partition Pruning
|
18.4.1 分区剪除
|
|
117 |
The Oracle database server explicitly recognizes partitions and
subpartitions. It then optimizes SQL statements to mark the partitions
or subpartitions that need to be accessed and eliminates (prunes)
unnecessary partitions or subpartitions from access by those SQL
statements. In other words, partition pruning is the skipping of
unnecessary index and data partitions or subpartitions in a query.
|
Oracle 数据库服务器能够识别出对象的分区(partition)及子分区(subpartition)。进而根据分区情况优化 SQL
语句,标识出需要存取的分区及子分区,不会存取不必要的分区及子分区(即剪除(prune))。也可以这样理解,分区剪除(partition
pruning)就是在查询中跳过不必存储的分区及子分区。
|
|
118 |
For each SQL statement, depending on the selection criteria specified,
unneeded partitions or subpartitions can be eliminated. For example, if
a query only involves March sales data, then there is no need to
retrieve data for the remaining eleven months. Such intelligent pruning
can dramatically reduce the data volume, resulting in substantial
improvements in query performance.
|
对于每个 SQL 语句,Oracle 能够根据用户设定的查询条件(selection
criteria),避免访问不需要的分区及子分区。例如,一个查询只需要三月份的销售数据,就不必获取其余十一个月的数据。这种智能剪除技术(intelligent
pruning)能够显著地减少数据访问量,从而大幅提升查询性能。
|
|
119 |
If the optimizer determines that the selection criteria used for pruning
are satisfied by all the rows in the accessed partition or subpartition,
it removes those criteria from the predicate list (WHERE
clause) during evaluation in order to improve performance. However, the
optimizer cannot prune partitions if the SQL statement applies a
function to the partitioning column (with the exception of the
TO_DATE function). Similarly, the optimizer
cannot use an index if the SQL statement applies a function to the
indexed column, unless it is a function-based index.
|
如果优化器(optimizer)在剪除过程中确定某些分区或子分区中的全部数据与某些查询条件相对应,她在评估语句时将从谓项列表(predicate
list)(即 WHERE
子句)中移除这些查询条件,从而提升语句的执行性能。但是,如果用户在 SQL 语句中的分区键上使用了函数(TO_DATE
除外),优化器将无法对相关分区进行分区剪除。与此类似的是,如果用户在 SQL 语句中的索引键上使用了函数(函数索引(function-based
index)除外),优化器也将无法使用相关的索引。
|
|
120 |
Pruning can eliminate index partitions even when the underlying table's
partitions cannot be eliminated, but only when the index and table are
partitioned on different columns. You can often improve the performance
of operations on large tables by creating partitioned indexes that
reduce the amount of data that your SQL statements need to access or
modify.
|
如果表及其上的索引依据不同列进行分区,在查询器优化查询时即使不能对表分区进行剪除,也可以对索引分区进行剪除。用户创建分区索引后,就能有效减少
SQL 语句所需存取的数据量,从而提升在大数据量表上执行操作的性能。
|
|
121 |
Equality, range, LIKE, and
IN-list predicates are considered for
partition pruning with range or list partitioning, and equality and
IN-list predicates are considered for
partition pruning with hash partitioning.
|
对于相等(equality),范围(range),LIKE,及
IN-列表(list)等谓词可以考虑通过范围分区(range
partitioning)或列表分区(list partitioning)来实现分区剪除;对于相等,IN-列表等谓词还可以通过范哈希分区(hash
partitioning)来实现分区剪除。
|
|
122 |
Partition Pruning Example
|
18.4.1.1 分区剪除示例
|
|
123 |
We have a partitioned table called cust_orders. The partition key for
cust_orders is order_date. Let us assume that cust_orders has six months
of data, January to June, with a partition for each month of data. If
the following query is run:
|
现有分区表(partitioned table)cust_orders,其分区键(partition key)为 order_date。假设
cust_orders 表中存储了从一月到六月的数据,每个月的数据存储在一个分区中。当执行以下语句时:
|
|
124 |
SELECT SUM(value)
FROM cust_orders
WHERE order_date BETWEEN '28-MAR-98' AND '23-APR-98';
|
SELECT SUM(value)
FROM cust_orders
WHERE order_date BETWEEN '28-MAR-98' AND '23-APR-98';
|
|
125 |
Partition pruning is achieved by:
- First, partition elimination of January, February, May, and June
data partitions. Then either:
- An index scan of the March and April data partition due to
high index selectivity
or
- A full scan of the March and April data partition due to
low index selectivity
|
分区剪除(partition pruning)的过程如下:
- 首先,跳过对一月,二月,五月,及六月分区的访问。然后:
- 如果索引的选择性较高(high index selectivity),则对三月及四月的数据分区进行索引扫描(index
scan)
或
- 如果索引的选择性较低(low index selectivity),则对三月及四月的数据分区进行全表扫描(full
scan)
|
|
126 |
Partition-wise Joins
|
18.4.2 基于分区的关联
|
|
127 |
A partition-wise join is a join optimization for joining two tables that
are both partitioned along the join column(s). With partition-wise
joins, the join operation is broken into smaller joins that are
performed sequentially or in parallel. Another way of looking at
partition-wise joins is that they minimize the amount of data exchanged
among parallel slaves during the execution of parallel joins by taking
into account data distribution.
|
基于分区的关联(partition-wise
join)是指,当两个分区表相互关联的列分别对应各自的分区键时而采取的关联优化措施。采用了基于分区的关联后,关联操作可以被分解为多个子操作,并可采用串行(sequentially)或并行(parallel)的执行方式。也可以从另一个角度看待基于分区的关联所做的优化工作,即此功能通过将数据处理均匀分布给多个子进程,减少了并行关联过程中各个子进程间的数据交换量。
|
|
128 |
See Also:
Oracle Database Data Warehousing Guide for more information
about partitioning methods and partition-wise joins
|
另建:
Oracle Database Data Warehousing Guide
了解分区方式及基于分区的关联
|
|
129 |
Parallel DML
|
18.4.3 并行 DML
|
|
130 |
Parallel execution dramatically reduces response time for data-intensive
operations on large databases typically associated with decision support
systems and data warehouses. In addition to conventional tables, you can
use parallel query and parallel DML with range- and hash-partitioned
tables. By doing so, you can enhance scalability and performance for
batch operations.
|
对于大型数据库中的大数据量操作,并行执行能够显著地缩短响应时间,这个特点在决策支持系统(decision support
systems,DDS)及数据仓库系统中表现的尤为突出。除了传统数据表之外,用户还可以对范围分区表(range-partitioned
table)及哈希分区表(hash-partitioned table)执行并行查询及并行 DML
操作。利用分区表的特性,用户可以提高数据批处理操作的可伸缩性及执行性能。
|
|
131 |
The semantics and restrictions for parallel DML sessions are the same
whether you are using index-organized tables or not.
|
无论用户是否使用索引表(index-organized table),并行 DML 操作的语法及限制条件都是相同的。
|
|
132 |
See Also:
Oracle Database Data Warehousing Guide for more information
about parallel DML and its use with partitioned tables
|
另见:
Oracle Database Data Warehousing Guide
了解并行 DML 及如何结合分区表使用并行 DML
|
